论文来自:
Xu H, Xiang L, Huang F, et al. Grace: Graph self-distillation and completion to mitigate degree-related biases[C]//Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2023: 2813-2824.
摘要
真实世界图普遍呈现长尾度分布(long-tail degree distribution),大量节点为低度节点(low-degree nodes)。尽管 GNN 在节点分类任务上表现出色,但其性能严重依赖丰富连接,对低度节点表示不足,导致显著的度相关偏差(degree-related bias)。
本文提出 Grace,通过以下两大机制缓解该问题:
- 自蒸馏(Graph Self-Distillation):增强低度节点的自表示能力(self-representation)
- 图补全(Graph Completion):提升低度节点的邻域同质性比率(Neighborhood Homophily Ratio, NHR)
结合 标签传播(Label Propagation) 防止错误传播。实验表明,Grace 在平衡整体性能与低度节点准确率方面显著优于现有方法。
问题背景与动机
图1:真实图的度分布与性能偏差
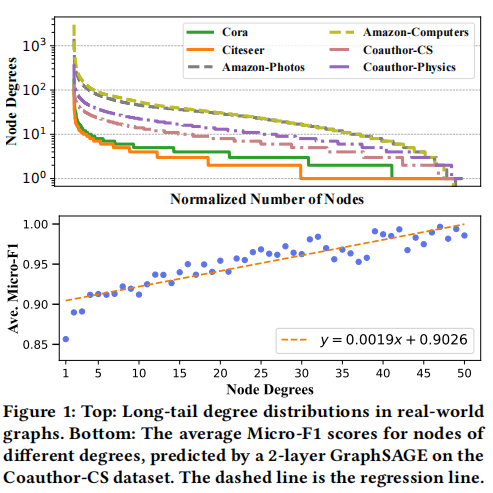
核心挑战
| 挑战 | 描述 |
|---|---|
| ① 自表示不足 | GNN 过度依赖邻域聚合,低度节点失去邻域后性能崩塌至 MLP 水平 |
| ② 低 NHR | 低度节点邻居中同类节点比例极低,违反 GNN 的同质性假设 |
整体框架
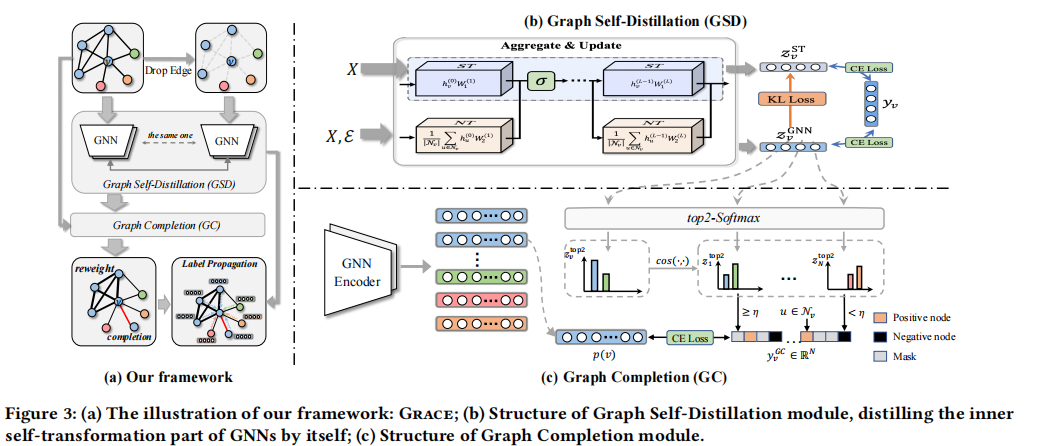
流程
- 分解 GNN 将 GNN 分成 ST(自变换,MLP) 和 NT(邻域变换) 两部分。
- 自蒸馏训练
- 教师模型:完整 GNN(ST + NT)
- 学生模型:仅 ST(退化为 MLP)
- 用教师软标签 + 真实标签监督学生,优化 ST 学习“邻域平移”。
- 图补全(Graph Completion)
- 对低度节点 $ v $,用自蒸馏输出 $ p(v) $ 预测同类邻居
- 建模为多标签任务:正样本=当前邻居,负样本=低相似度节点
- 选前 $ k $ 个高概率同类节点,添加新边,构建新图 $ G’ $。
- 训练 Grace-GNN 在补全后的图 $ G’ $ 上,用增强的 ST + NT 训练最终 GNN。
- 推理阶段:标签传播
- 对低度节点,用 $ p(v) $ 选前 $ k $ 个邻居
- 构建有向边(高置信 → 低度)
- 单跳传播: $\hat{p}(v) = (1-\lambda) p(v) + \lambda \sum_{u \to v} p(u)$
- 输出最终预测。
核心特点:自蒸馏增强自表示 + 精准补全提升 NHR + 单跳传播防误传,实现低度节点性能大幅提升,整体无损。
核心模块
自蒸馏(Graph Self-Distillation)
思路
将 GNN 分解为两部分:
- ST(Self-Transformation):节点自身特征变换(MLP)
- NT(Neighborhood Transformation):邻居信息聚合
目标:将图依赖性从 NT 迁移到 ST,使 ST 学习到“邻域平移”
实现
- 教师模型:完整 GNN(含 ST + NT)
- 学生模型:仅 ST 部分(退化为 MLP)
- 训练流程:
- 输入节点特征 → 教师模型 → 软标签 $ p_t(v) $
- 输入相同特征 → 学生模型 → 输出 $ p_s(v) $
- 损失: $\mathcal{L}_{KD} = \sum_v \left[ \alpha \cdot KL(p_t(v) | p_s(v)) + (1-\alpha) \cdot CE(p_s(v), y_v) \right]$
收敛后,ST 隐式编码了邻域信息,增强低度节点自表示
图补全(Graph Completion)
目标
为低度节点预测同类潜在邻居,提升 NHR
建模为多标签预测任务
- 正样本:当前邻居 $ \mathcal{N}(v) $
- 候选负样本:其他节点
- 预测:使用自蒸馏输出的软标签 $ p(v) $
- 选择策略:
- 取 $ p(v) $ 中前 2 大概率类别
- 归一化得到权重
- 负样本:与 $ v $ 余弦相似度 < $ \eta $
- 最终标签: $y_v^{\text{multi}} = \text{softmax}\left( \sum_{u \in \mathcal{N}(v)} p(u) \right)$
仅连接最可能同类的节点,避免噪声
标签传播(Label Propagation)
作用
防止图补全中的误分类传播
预测阶段流程
- 根据 $ p(v) $ 选前 $ k $ 个潜在邻居
- 构建有向边:$ u \to v $($ u $ 是高置信邻居)
- 单跳传播: $\hat{p}(v) = (1 - \lambda) p(v) + \lambda \sum_{u \in \mathcal{N}’(v)} p(u)$ 其中 $ \mathcal{N}’(v) $ 为新图中的邻居
信息单向流动:从可靠节点 → 低度节点
符号表
| 符号 | 含义 |
|---|---|
| $ G = (V, E, X, Y) $ | 原始图 |
| $ \deg(v) $ | 节点 $ v $ 的度数 |
| $ \text{NHR}(v) $ | 邻域同质性比率 = 同类邻居数 / 总邻居数 |
| $ \text{ST}(\cdot), \text{NT}(\cdot) $ | 自变换、邻域变换 |
| $ p_t(v), p_s(v) $ | 教师/学生模型输出概率 |
| $ \mathcal{L}_{KD} $ | 知识蒸馏损失 |
| $ \eta $ | 负样本相似度阈值 |
| $ k $ | 预测邻居数量 |
| $ G’ $ | 补全后新图 |
| $ \mathcal{N}’(v) $ | 新图中 $ v $ 的邻居集 |